Name
In Kubernetes, each resource object has a unique name and UID. The name can be client-specified. The UID is assigned by Kubernetes.
Namespace
Resource objects are scoped within namespaces. Each namespace is a virtual cluster, backed by a physical cluster. Kubernetes supports multiple namespaces. Resource names must be unique within a namespace, but not across all namespaces. Kubernetes provides two initial namespaces:
- default: is the default namespace for objects with no other namespace, and
- kube-system: is the namespace for Kubernetes-generated objects. You can use namespaces to divide cluster resources according to use, and limit resource consumption by using resource quotas.
Not all Kubernetes objects are in a namespace. Low-level resources, such as nodes, persistent volumes, and namespaces themselves are not in a namespace.
Label
A Label is another way of identifying an object within a namespace. You can use Labels to map your own organizational structures onto objects. A Label is a key/value pair that can be attached to an object such as a Pod, to identify it in a meaningful or relevant way. The Label key must be unique for each object. There are also rules for syntax and character set that you can look up in the Kubernetes documentation.
Labels do not provide uniqueness (like a name or UID does), and it’s possible to have many objects with the same Label.
# Label syntax
"labels": {
"key1" : "value1",
"key2" : "value2" }
Selector
Selectors can be used with labels to identify and collect resource objects according to some criteria. A selector can include one or more requirements, separated by commas. To fulfill the Selector, all requirements must be satisfied, so the comma acts as an AND operator.
An empty Label Selector (that is, one with zero requirements) selects every object in the collection.
A null Label Selector (which is only possible for optional Selector fields) selects no objects.
Kubernetes supports two types of Selectors: equality-based and set-based.
- equality-based: filters by Label keys and values. It accepts the operators = (equal to), and != (not equal to).
- set-based: filters keys according to a set of values. It accepts the operators: in, notin (one word), and exists.
Label selectors must not overlap within a namespace, otherwise they will conflict with each other.
# Equality-based selectors
environment = production
tier != frontend
# Set-based selectors
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
Annotation
Another way to attach metadata to an object is by using an Annotation. You can use tools and libraries to retrieve this metadata, but it can not be used to identify and select objects in the way that Labels can. Instead, an Annotation can be either structured or unstructured, and include characters that labels can not. For example, you can record build or release information such as timestamps, version numbers, git branch, and so on. The syntax for Annotations is similar to Labels.
# Annotation syntax
"annotations": {
"key1" : "value1",
"key2" : "value2" }
Resource quota
Administrators can use resource quotas (defined by a ResourceQuota object) to limit the resources that can be consumed in a namespace. This limit can be applied to the number of resource objects that can be created in a namespace, and the compute resources (CPU, memory) that those objects use. This tool can be useful in environments where a number of developers or teams share a cluster with a fixed number of Nodes.
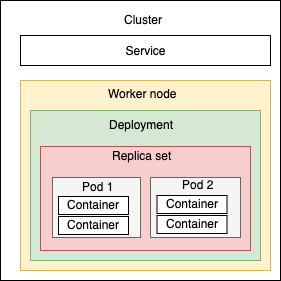
Service
A Service is an abstraction that defines a set of Pods and a policy by which to access them. A Service targets a set of Pods, typically by using a label selector. The service can be exposed in a number of ways:
- Cluster internal IP address
- Node IP address at a static port
- Externally, by using a cloud provider’s load balancer
- External name, such as myservice.example.com
Kubernetes assigns an internal cluster IP address to the Service. The kube-proxy, which runs on each node in a cluster, uses this IP address to direct traffic on the node.
For Kubernetes-native applications, Kubernetes offers a simple Endpoints API that is updated whenever the set of Pods in a service changes. For non-native applications, Kubernetes offers a virtual-IP-based bridge to Services, which redirects to the back-end Pods.
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
Secret
The Secret object can be used to hold sensitive information, such as passwords, OAuth tokens, and ssh keys (instead of putting this information directly into a pod or an image). For example, if a Pod needs to access a database, and the username and password that the Pod should use is stored in a couple of local files. You can create a Secret object that packages these files.
A Pod must reference a Secret to use it, and can either reference it as a file in a volume that is mounted on one or more containers in the pod, or the Secret can be exposed as an environment variable, and the kubelet can use it when pulling images for the Pod.
Service accounts automatically create and attach Secrets with API Credentials. Kubernetes automatically creates Secrets that contain credentials for accessing the API, and it modifies your Pods to use this type of Secret.
Deployment
A Deployment object is a Kubernetes resource (YAML file) where you specify your containers and other Kubernetes resources that are required to run your application. Basically, you describe the “desired state” in the Deployment, and a Deployment controller rolls out the changes to create this state. You can also use Deployments to create ReplicaSets.
ReplicaSet
A ReplicaSet uses Pod templates to define a set of Pod replicas. A Pod template describes what a Pod should contain. The ReplicaSet ensures that the specified number of Pod replicas are running at any given time. ReplicaSets can be used directly, but are typically used with Deployments to orchestrate the Pod lifecycle.